Wie funktionieren Chatbots?
18 August, 2025
Was sind Chatbots?
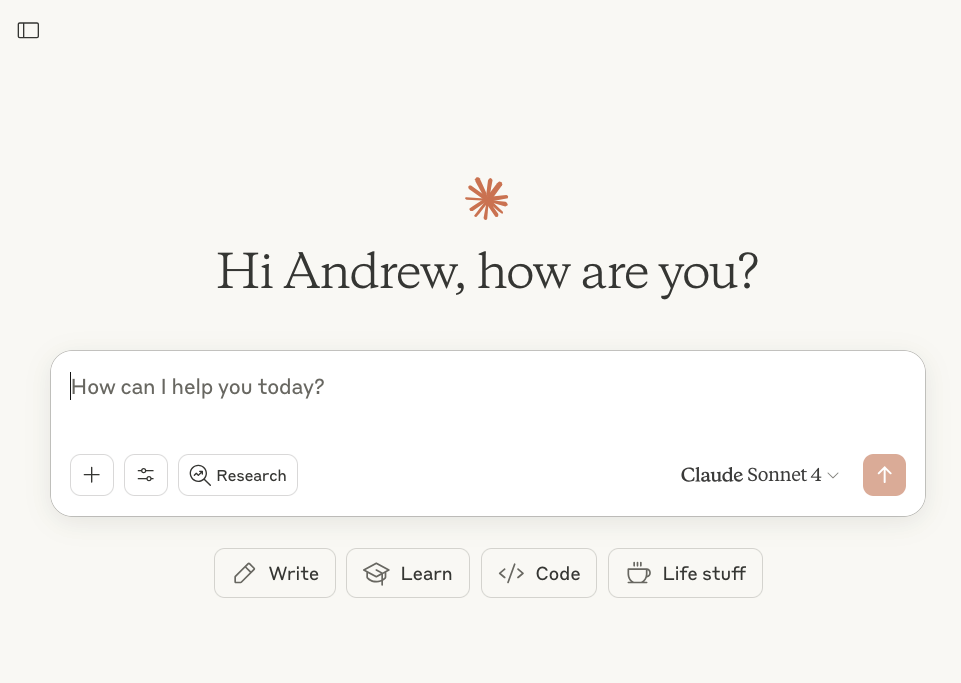
Was sind LLMs?
Ein LLM kann man sich wie einen ausgefeilten Autocomplete-Mechanismus vorstellen.
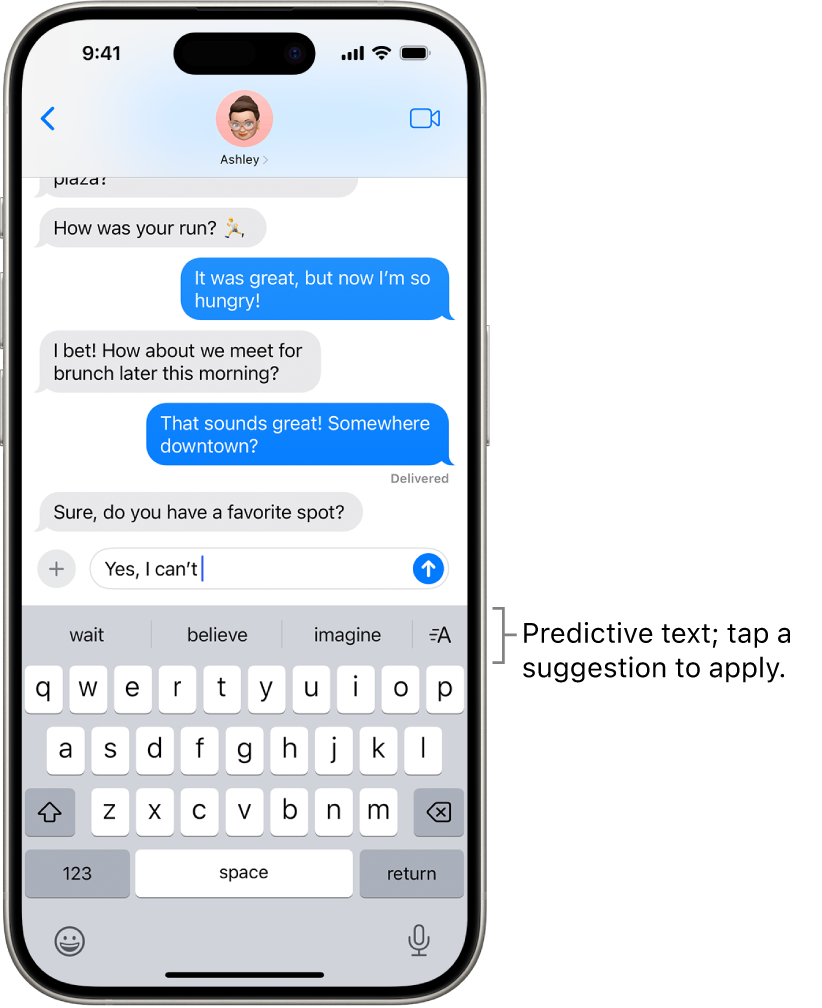
Bildquelle: www.apple.com
Wie generieren LLMs Text?
\[ \newcommand{\green}[1]{\color{green}{#1}} \newcommand{\purple}[1]{\color{purple}{#1}} \newcommand{\red}[1]{\color{red}{#1}} \newcommand{\blue}[1]{\color{blue}{#1}} \]
\[\green{P(\text{Wort}_{i+1}} \mid \red{\text{Kontext}}, \blue{\text{Modell}})\]
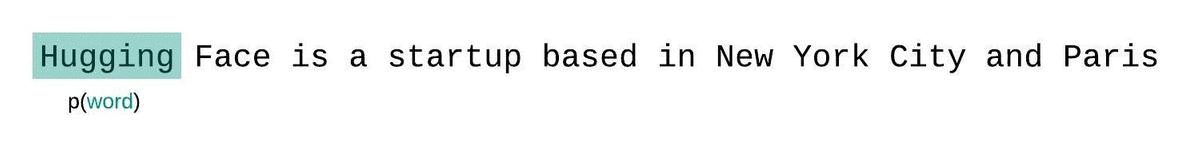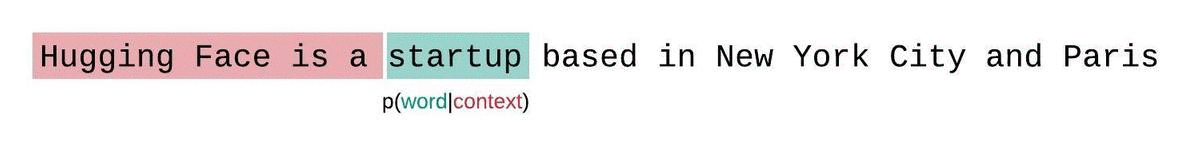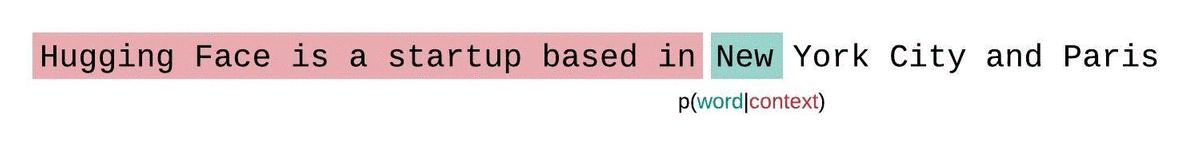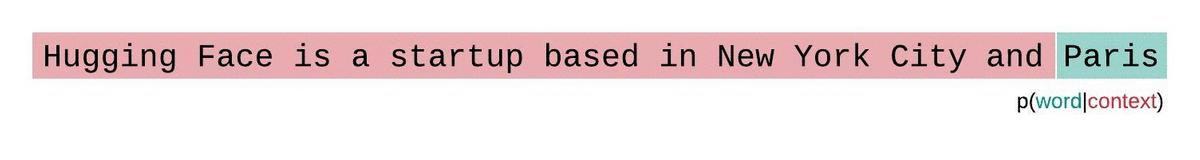
Wie werden LLMs trainiert?
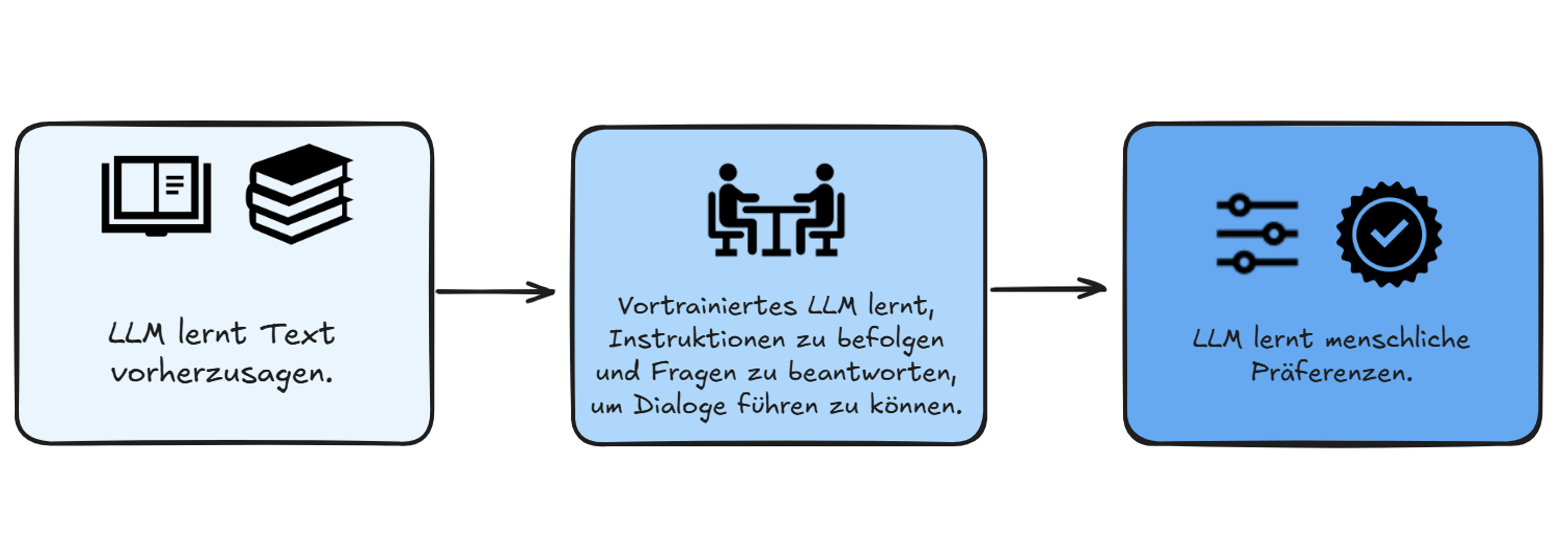
Gefahren und Herausforderungen
Die verschiedenen Stufen des Trainings sind mit verschiedenen Arten von Bedenken verbunden:
- Urheberrecht: Die trainierten Modelle werden mit Texten trainiert, die möglicherweise Urheberrechtlich geschützt sind.
- Bias: Die trainierten Modelle können bestehende Vorurteile aus den Trainingsdaten lernen.
- Energieverbrauch: Das Training der Modelle verbraucht viel Energie und ist damit umweltbelastend.
- Sycophancy: Die Modelle neigen dazu, die Meinungen oder Präferenzen ihrer Benutzer zu bestätigen.

Gefahren und Herausforderungen
- Obschon sich LLMs viel Wissen aneignen1, werden sie nicht trainiert, faktisch korrekte Aussagen zu machen.
- Dies bedeutet, dass wir alle Aussagen, die LLMs uns präsentieren, immer kritisch hinterfragen müssen.
- LLMs sind keine Wissensdatenbanken. Informationen immer anhand externer Quellen überprüfen.
ChatGPT
Fragen beantworten

Bilder analysieren

Dokumente zusammenfassen
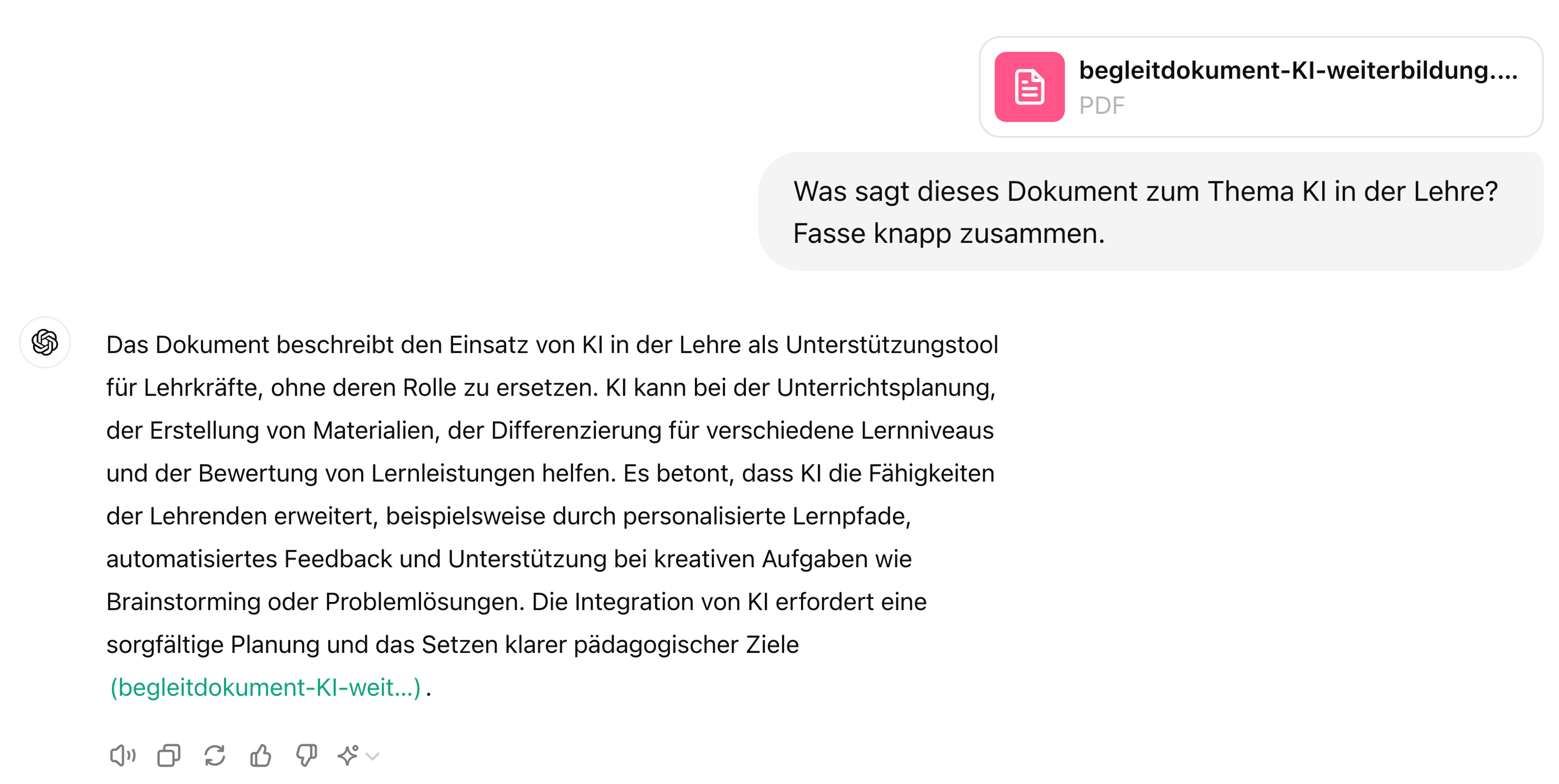
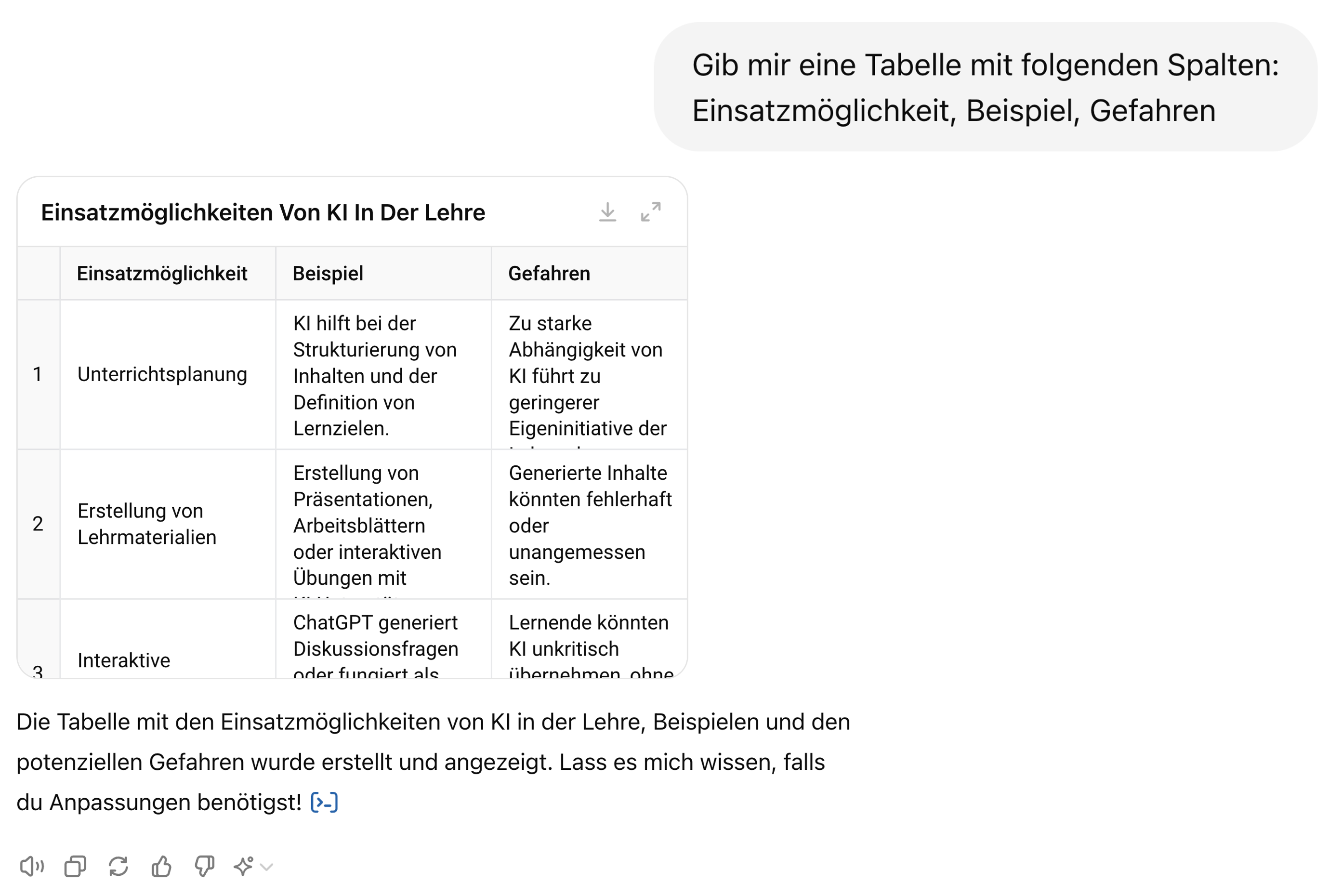
Output strukturieren
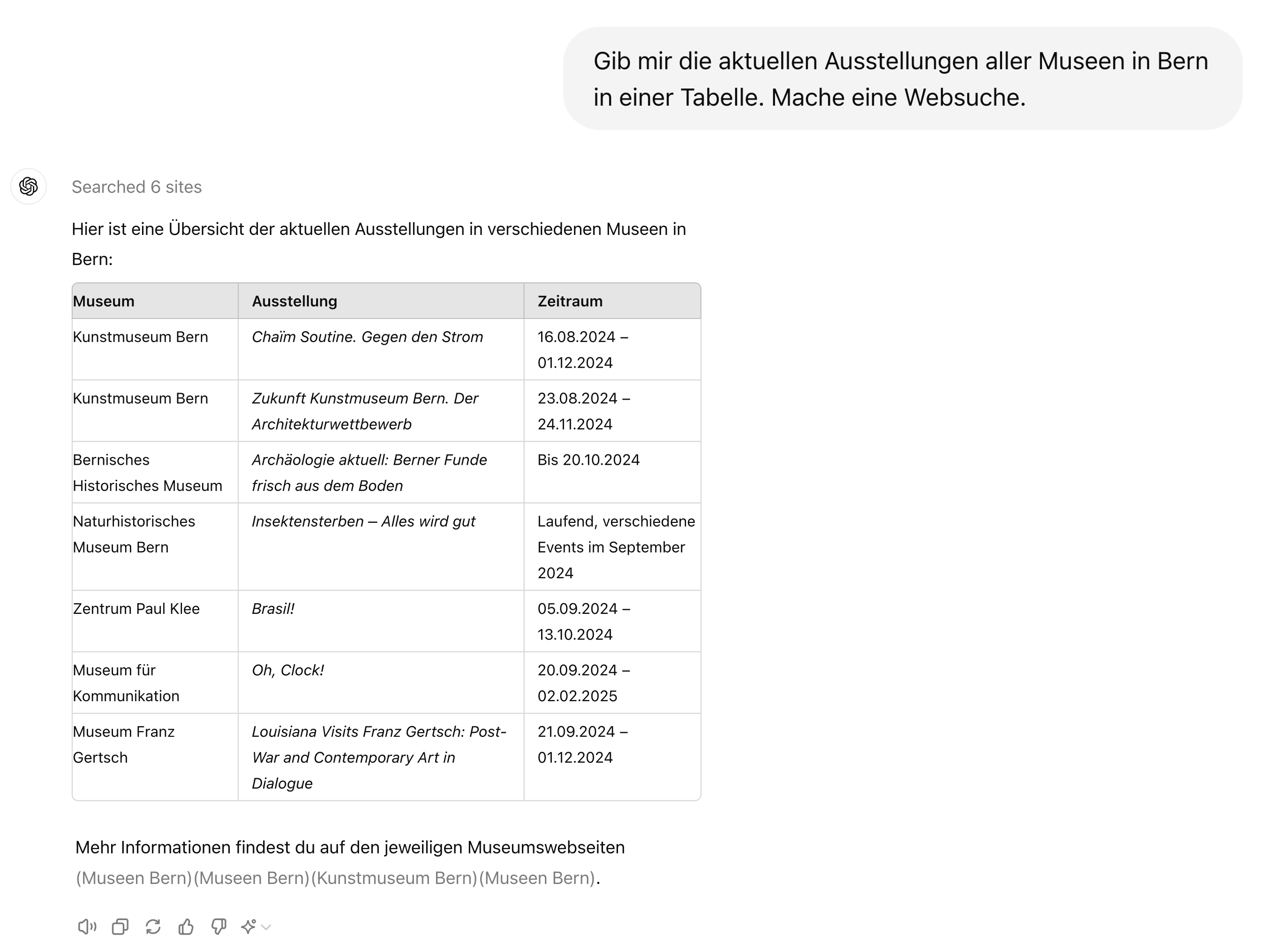
Websuche
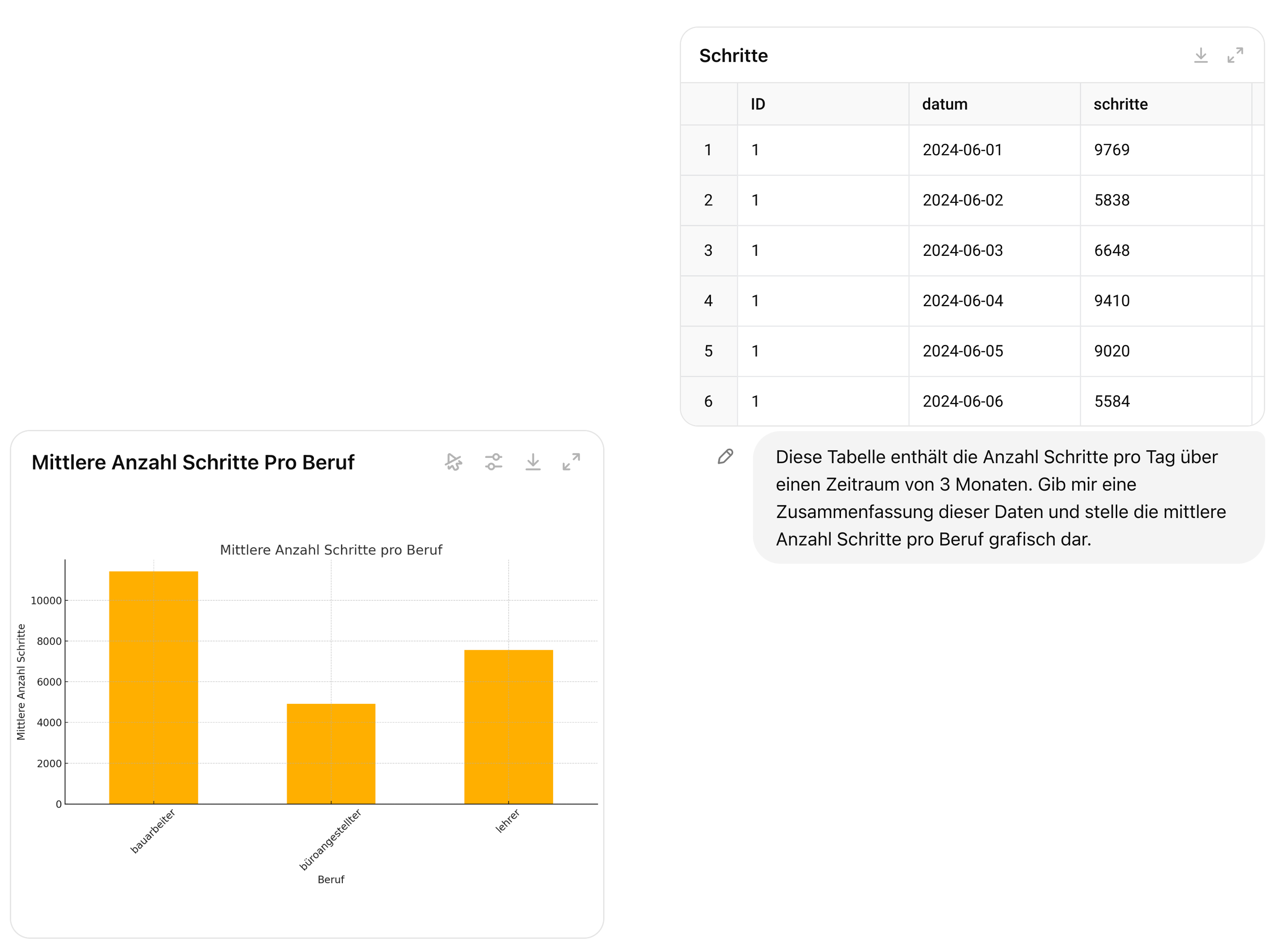
Datenanalyse
Custom GPTs
