KI: erste Schritte & rechtliche Aspekte
05 December, 2024
Large Language Models (LMMs)
Maschinelles Lernen:
Modelle, die ohne explizite Programmierung Muster aus Daten erlernen, um Vorhersagen oder Entscheidungen zu treffen. 
Large Language Model:
Ein maschinelles Lernmodell, das darauf trainiert wird, das nächste Wort nach einem Eingabetext (Prompt) vorherzusagen.

Körperliche Arbeit
19. Jahrhundert

20. Jahrhundert

Bildquelle: Erstellt mit DALL-E 3
Wie sieht das für die kognitive Arbeit aus?
1960

2030 
Bildquelle: Erstellt mit DALL-E 3
Ankunftstechnologien
Hochschulen stehen vor Herausforderungen mit Technologien wie ChatGPT, weil sie:
- Traditionelle Technologie-Evaluierungsprozesse umgehen
- Durch spontane Adoption eingeführt werden
- Reaktive statt proaktive Richtlinien erfordern

Bildquelle: Erstellt mit DALL-E 3 (“ChatGPT arriving at a university in the style of a 14th century painting.”)
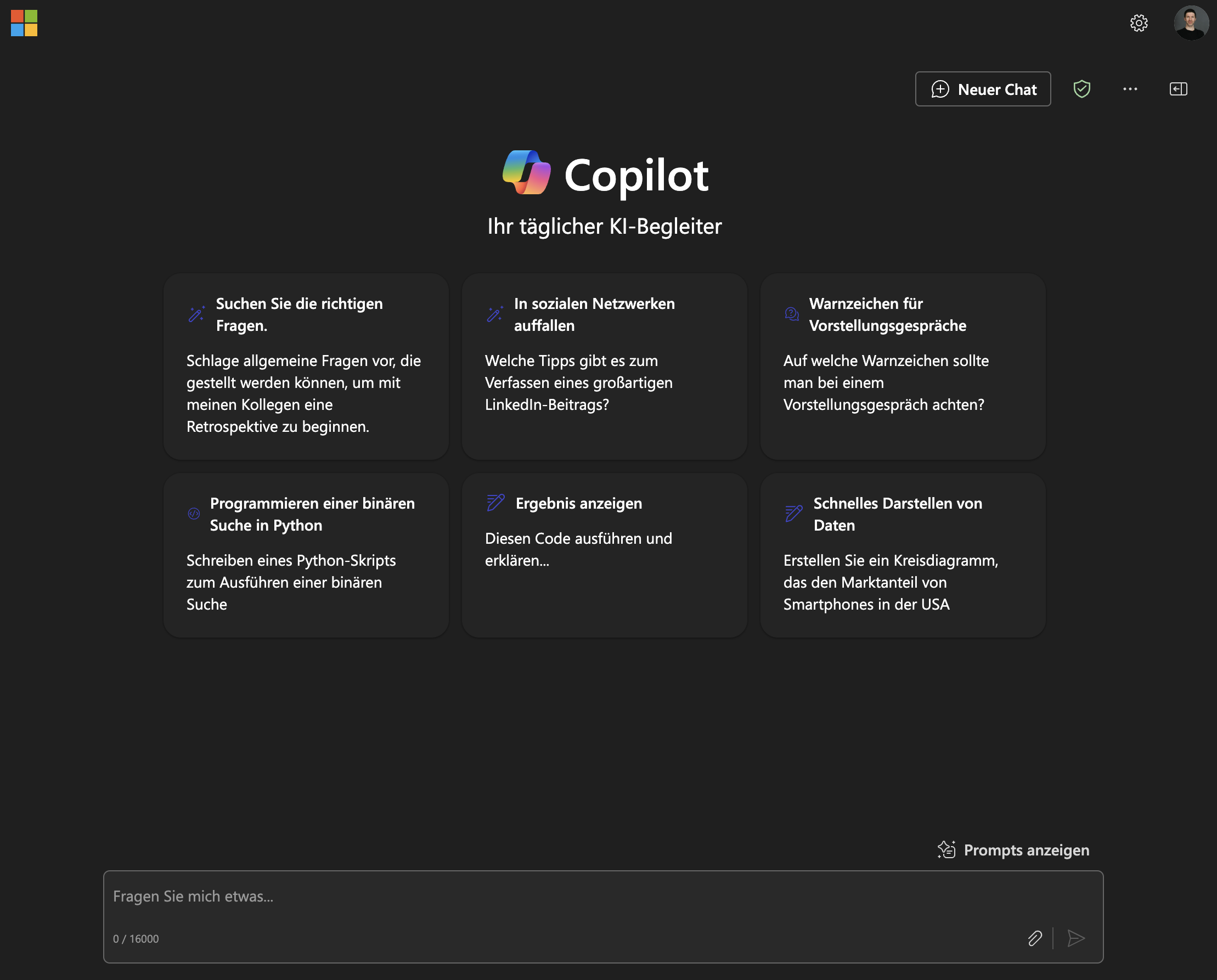
Was sind LLMs?
Ein LLM kann man sich wie einen ausgefeilten Autocomplete-Mechanismus vorstellen.
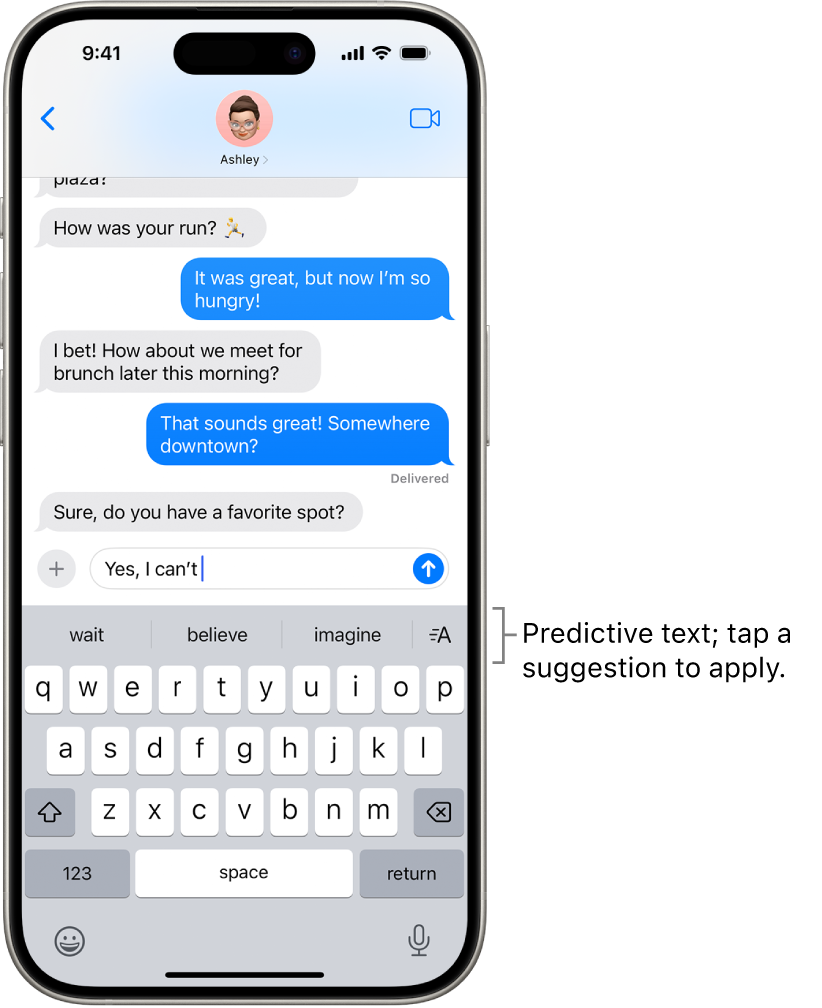
Bildquelle: www.apple.com
Wie generieren LLMs Text?
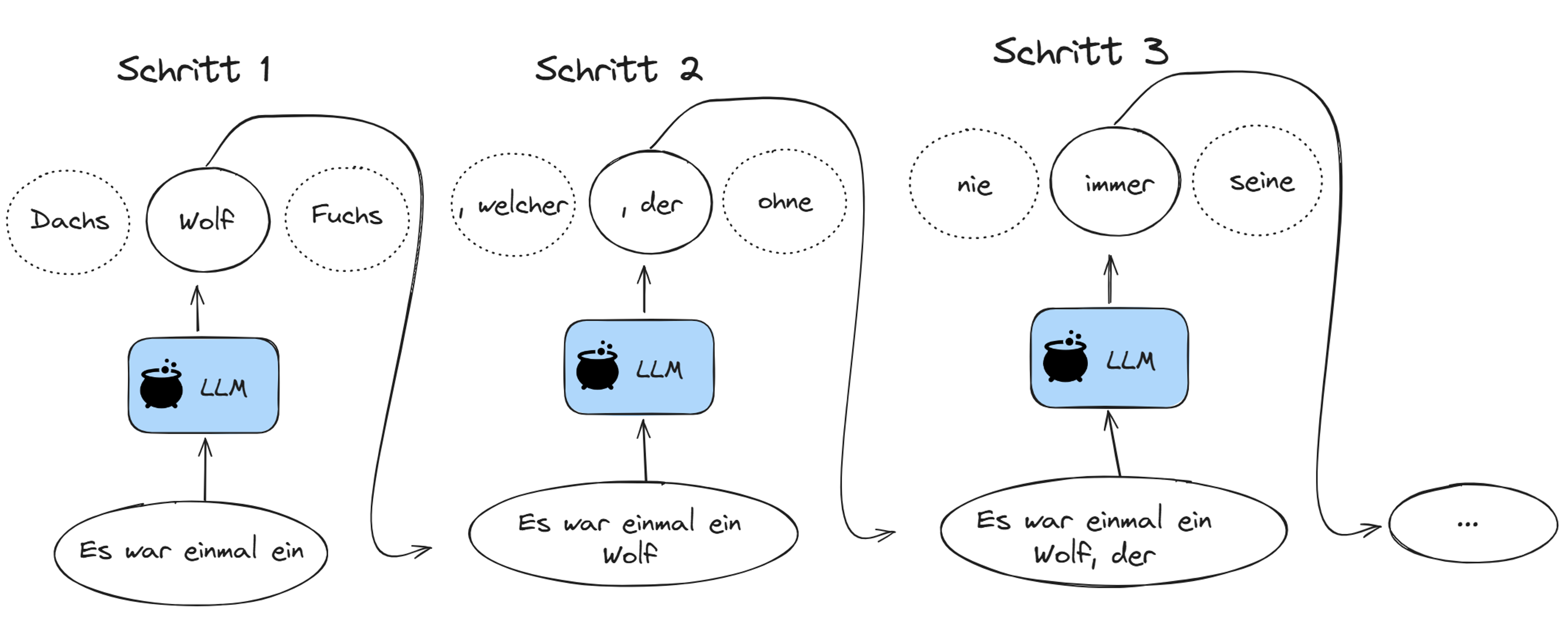
Wie können LLMs Text vorhersagen?
Sie werden trainiert, das nächste Wort in einer gegebenen Wortsequenz zu erraten.
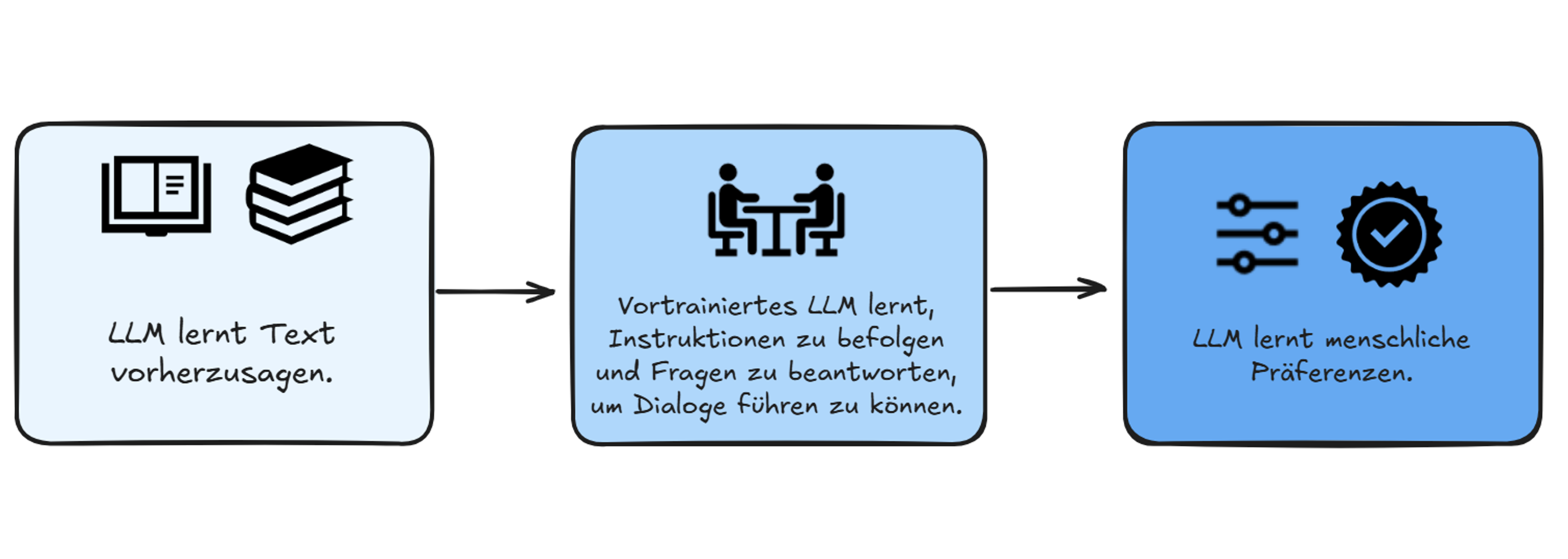
Ein LLM wird in drei Schritten aufgebaut:
- Sammeln eines grossen Text-Korpus.
- Basierend auf diesem Text, muss das Modell das nächste Wort in einer gegebenen Wortsequenz vorherzusagen lernen.
- Das Sprachmodell wird feiner abgestimmt, um das gewünschte Verhalten zu erreichen.

Wie werden LLMs trainiert?
Gefahren und Herausforderungen
Die verschiedenen Stufen des Trainings sind mit verschiedenen Arten von Bedenken verbunden:
- Urheberrecht: Die trainierten Modelle werden mit Texten trainiert, die möglicherweise Urheberrechtlich geschützt sind.
- Bias: Die trainierten Modelle können bestehende Vorurteile aus den Trainingsdaten lernen.
- Energieverbrauch: Das Training der Modelle verbraucht viel Energie und ist damit umweltbelastend.

Gefahren und Herausforderungen
- Obschon sich LLMs viel Wissen aneignen1, werden sie nicht trainiert, faktisch korrekte Aussagen zu machen.
- Dies bedeutet, dass wir alle Aussagen, die LLMs uns präsentieren, immer kritisch hinterfragen müssen.
- LLMs sind keine Wissensdatenbanken. Informationen immer anhand externer Quellen überprüfen.
ChatGPT
Fragen beantworten

Bilder analysieren

Dokumente zusammenfassen
Output strukturieren
Websuche
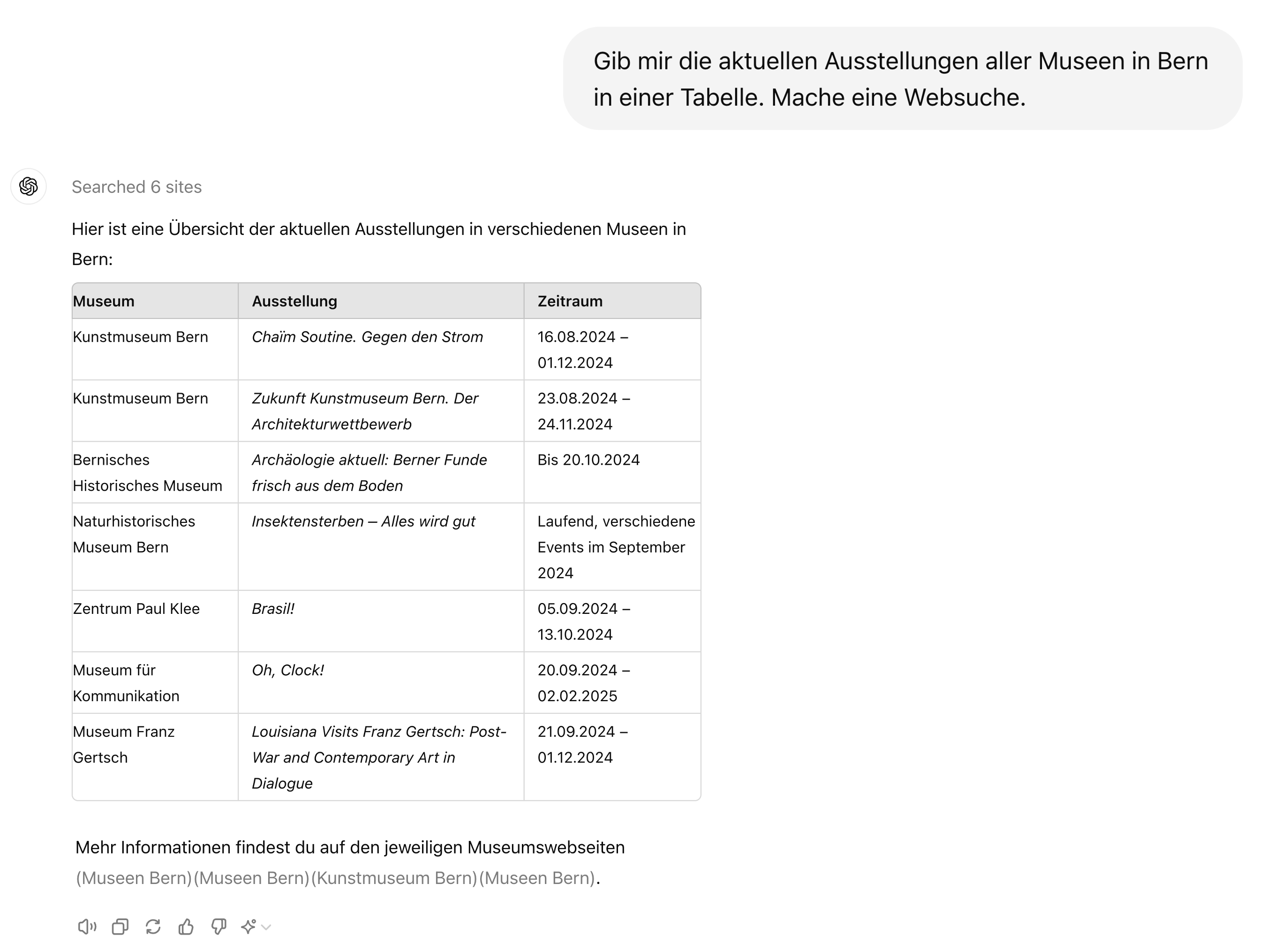
Datenanalyse
Custom GPTs

Schutzmassnahmen
Keine persönlichen Daten in die Eingabe von ChatGPT einfliessen lassen (nur anonymisierte Informationen)
Keine Eingabe von sensiblen oder vertraulichen Informationen (Informationen über gesundheitliche, finanzielle oder private Angelegenheiten)
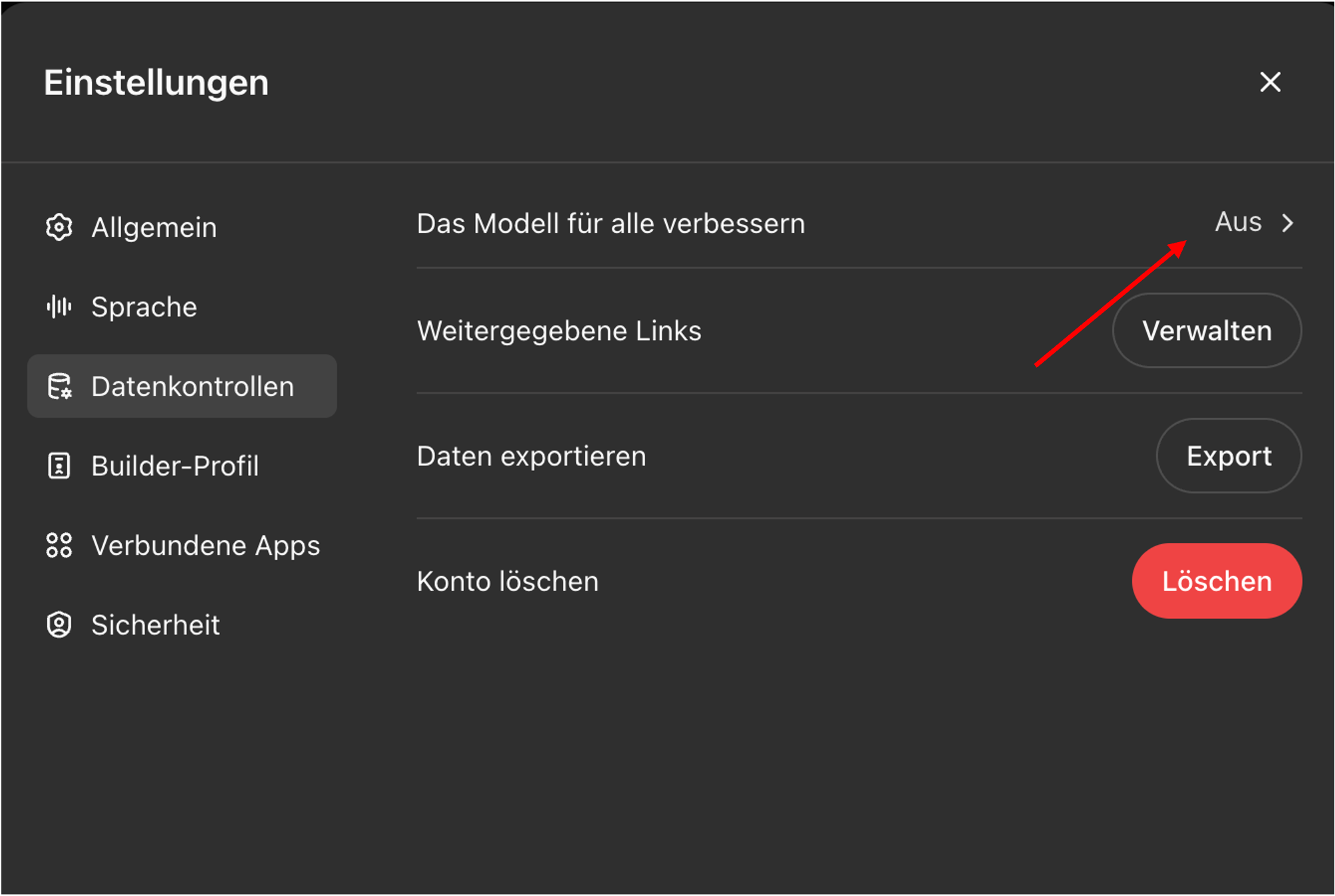
Einstellungen im Konto für Datenkontrolle:
Copilot verwenden
Microsoft Copilot garantiert, dass die Daten der Benutzer gesichert sind:
- Benutzerdaten sind durch Verschlüsselung, Sicherheitskontrollen und Datenisolation (gleich wie bei E-Mails in Exchange und Dateien in SharePoint) geschützt.
- Microsoft verwendet Daten nicht ohne Anweisung des Benutzers.