LLMs: Text representation, training, and text generation
23 October, 2023
Supervised learning

Classifiy pictures of cats and dogs: The goal of a model could be to discover which features distinguish cats from dogs.
Reinforcement learning

Text generation examples
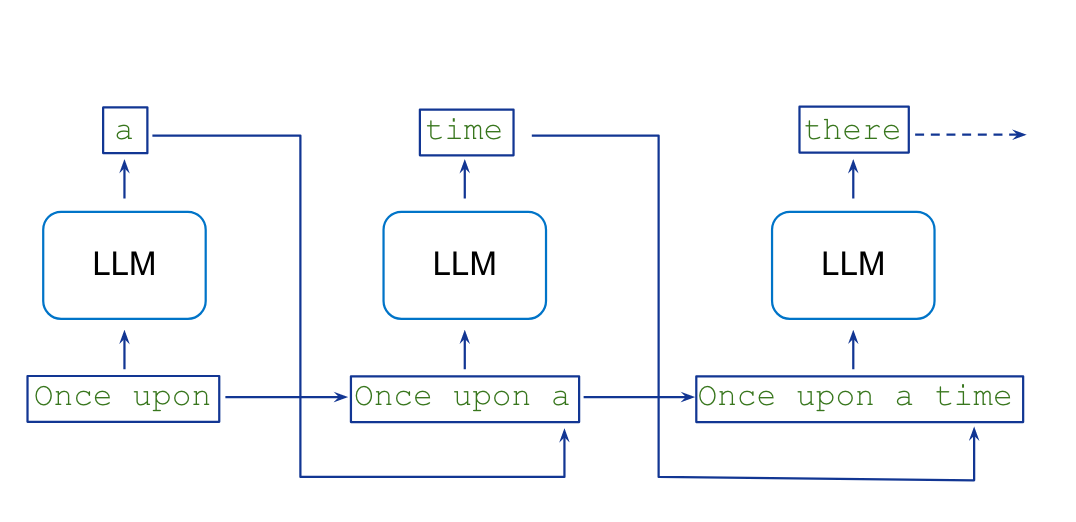
- The new context is used to generate the next token, etc.
- Every token is given an equal amount time (computation per token is constant). The model has no concept of more or less important tokens. This is crucial for understanding how LLMs work.
Tokenization
So far we have been talking about words, but LLMs operate with tokens. These are sub-words, and make working with text much easier for the model. A rule of thumb is that one token generally corresponds to ~4 characters of English text. This translates to roughly \(\frac{3}{4}\) of a word (so 100 tokens is about 75 words).
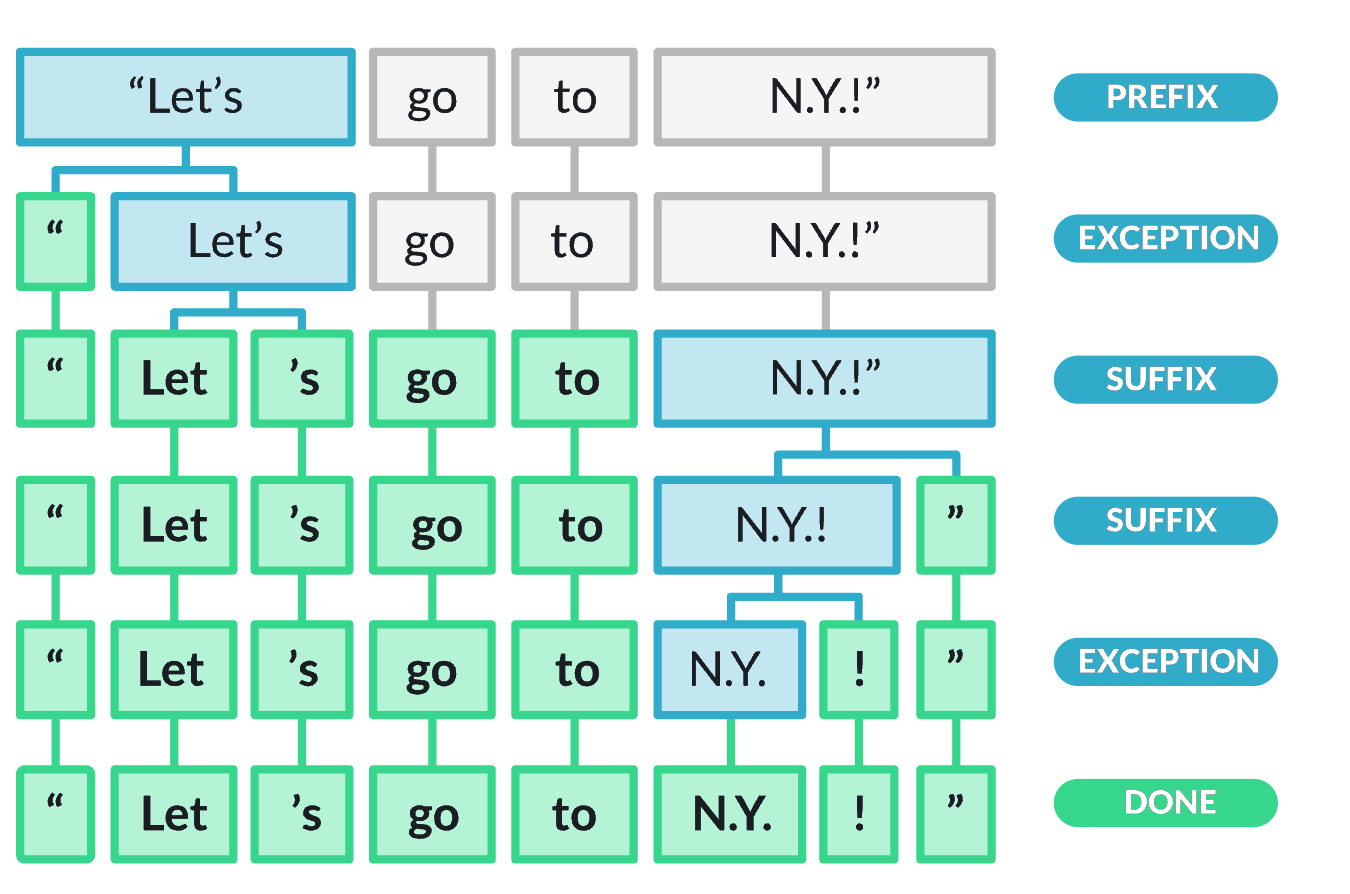
Feel free to try out the OpenAI tokenizer.
Embeddings
- The next step is to represent tokens as vectors.
- This is called “embedding” the tokens. The vectors are high-dimensional, and the distance between vectors measures the similarity between tokens.
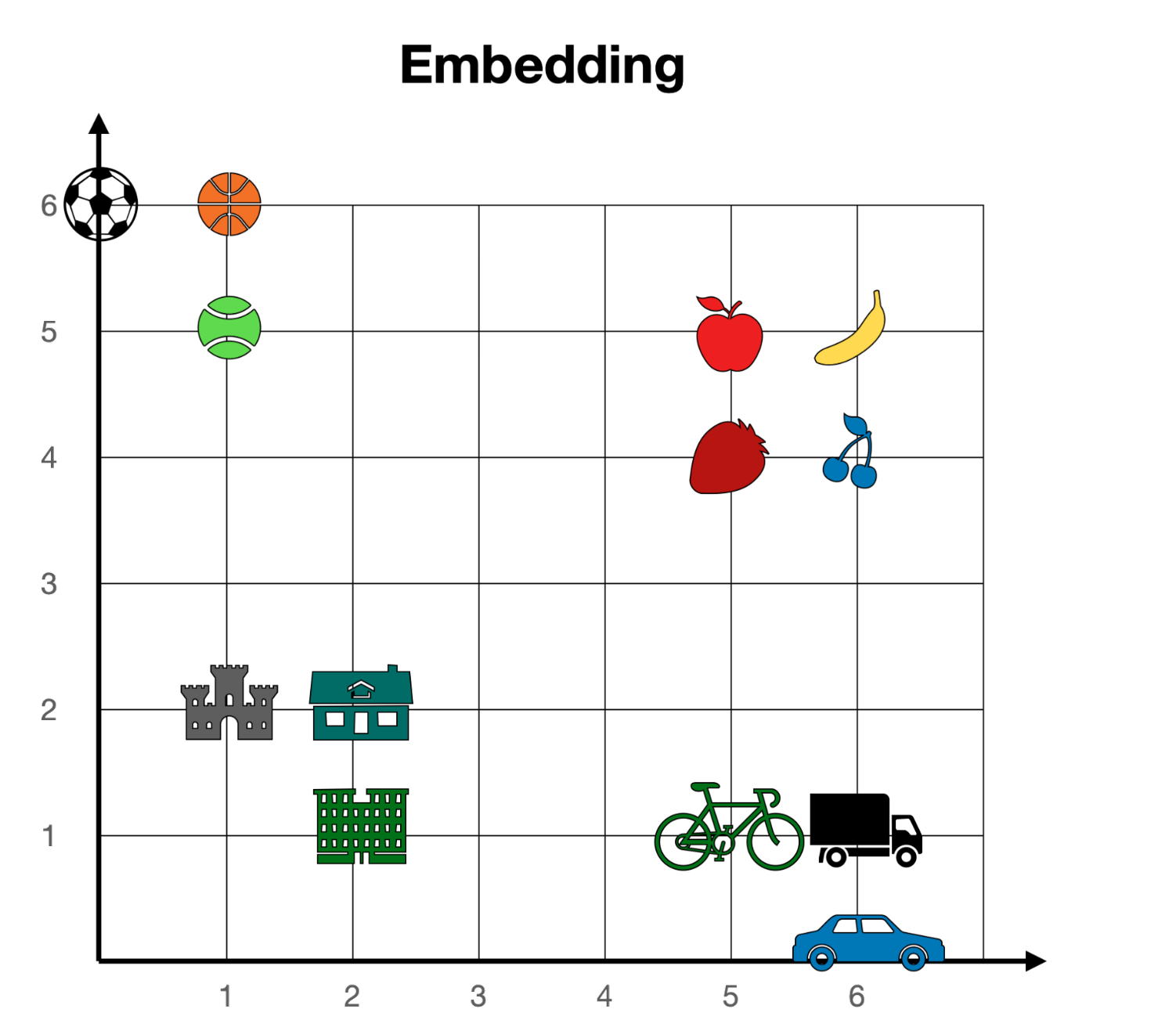
- In this 2-dimensional representation, concepts that are “related” lie close together.
You can read more about embeddings in this tutorial.
Pre-training Data

Pre-training

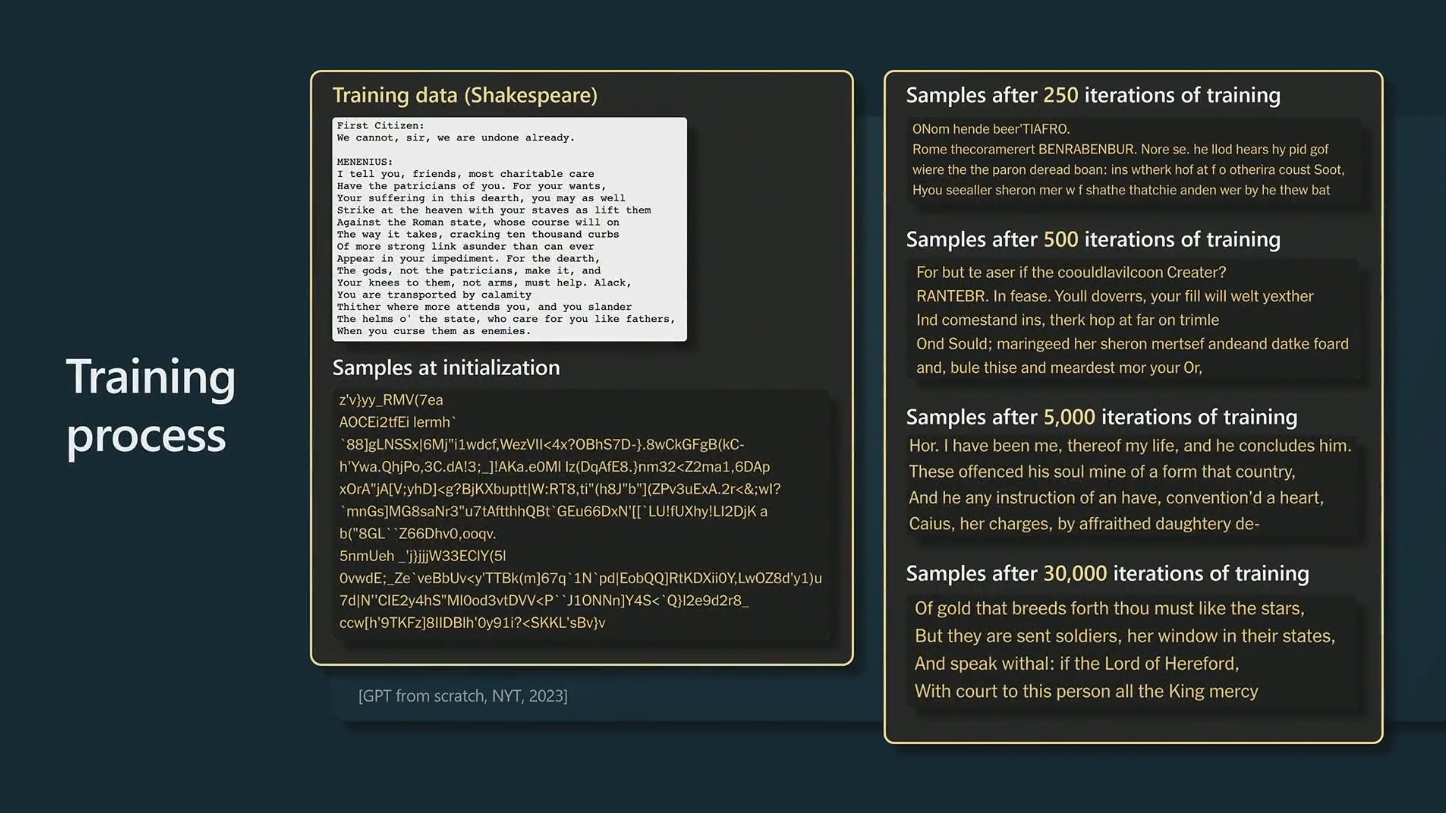
Supervised fine-tuning

Reinforcement learning from human feedback (RLHF)
Uses human feedback to rank the model’s responses. The goal is for the model to learn human preferences for responses.

Source: openai.com/blog/chatgpt
Role-Playing Simulator