The busy lecturer’s guide to LLMs
28 February, 2024
Training

How to train a language model

Example

What is learned?
- An LLM learns to predict the next word in a sequence, given the previous words: \[ P(word | context) \]
- Think of as “fancy autocomplete” (but very very powerful and sopisticated)
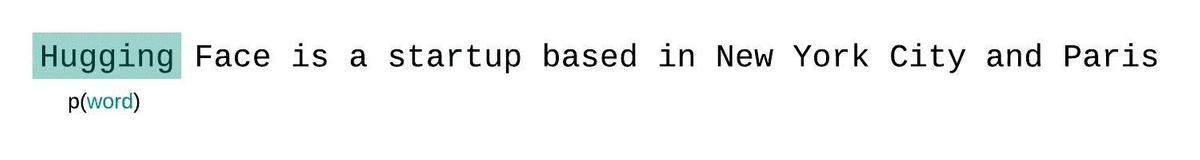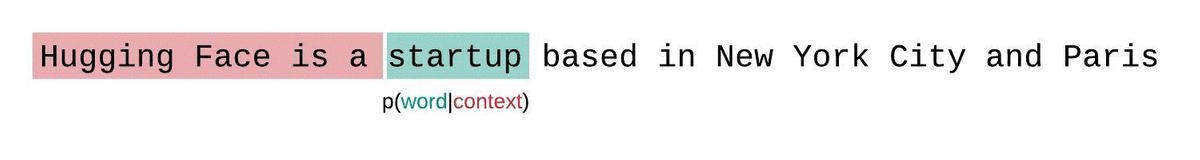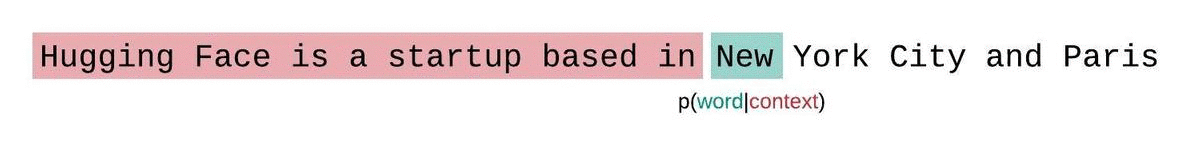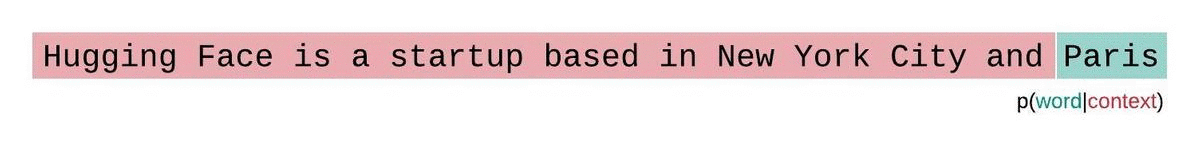
Text Generation

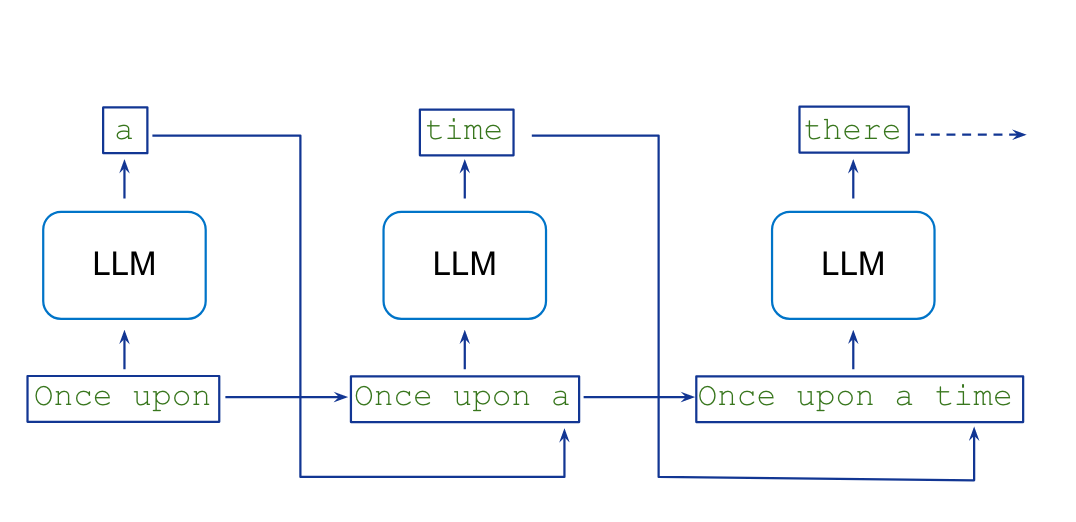
How does an LLM generate text?

Sampling

Auto-regressive generation
Tokenization
LLMs operate with tokens, not words. These are sub-words, and make working with text much easier for the model. A rule of thumb is that one token generally corresponds to ~4 characters of English text. This translates to roughly \(\frac{3}{4}\) of a word (so 100 tokens is about 75 words).
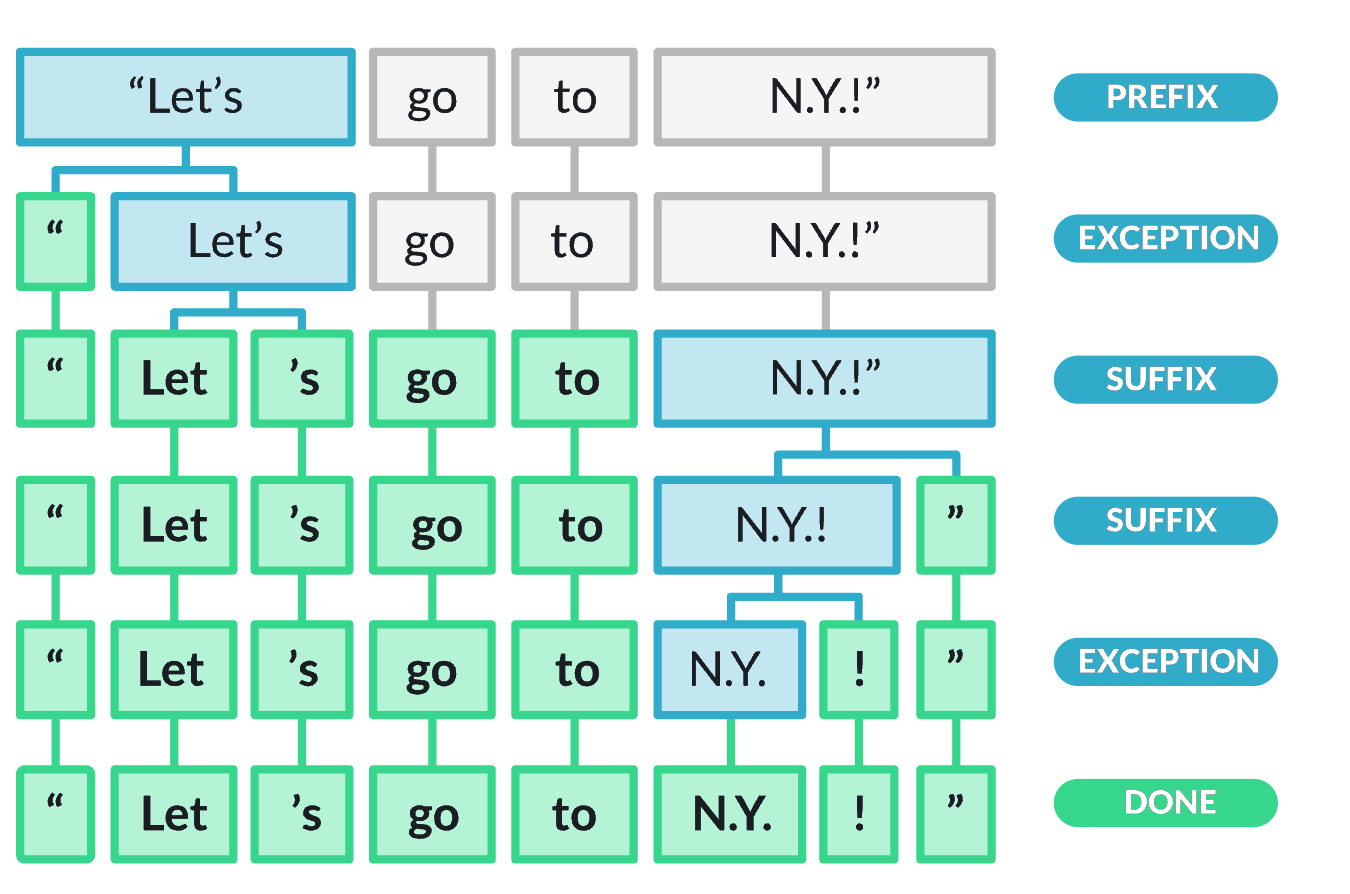
Feel free to try out the OpenAI tokenizer.
Training data

Figure courtesy of Andrej Karpathy
Training process
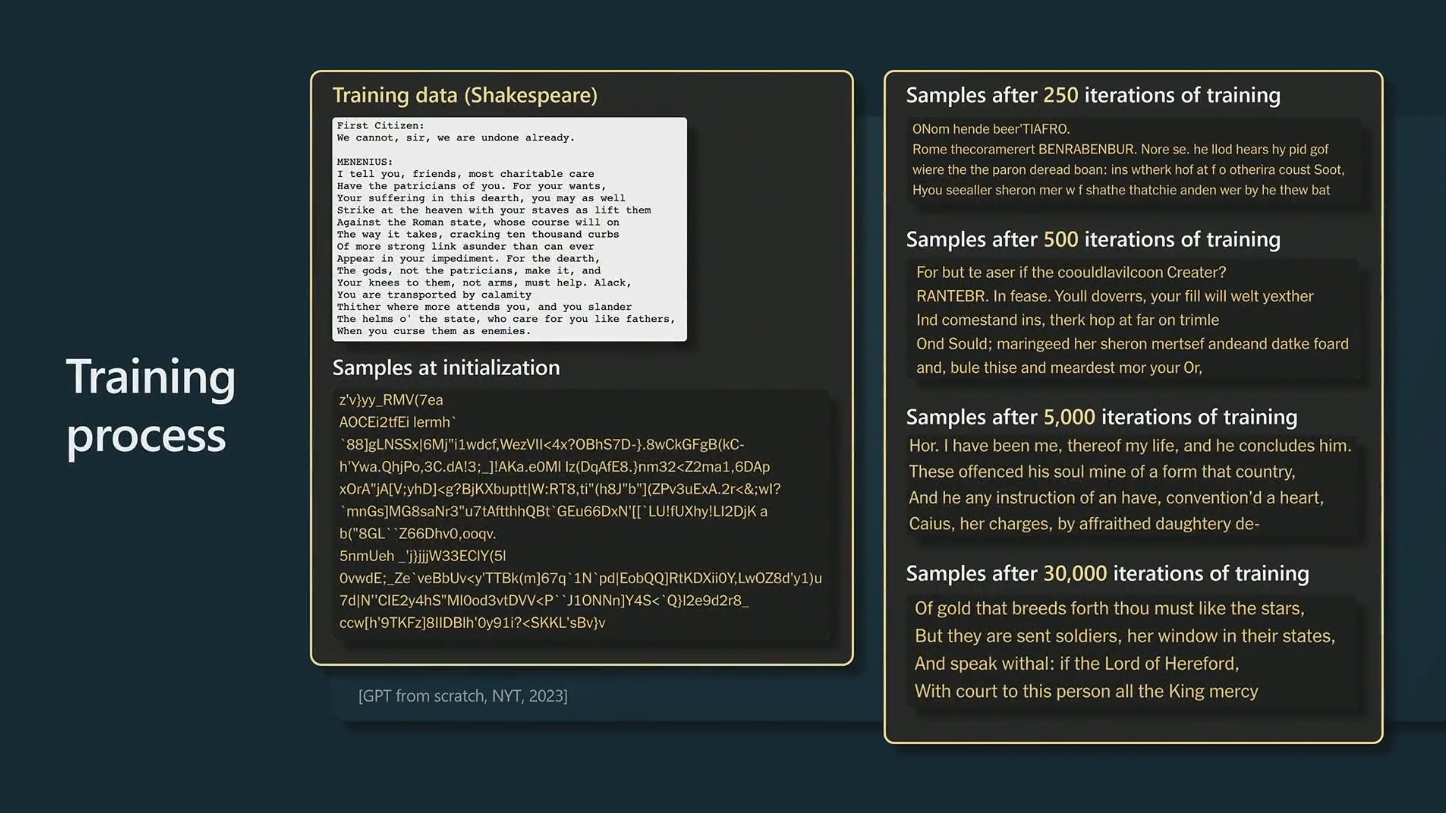
Figure courtesy of Andrej Karpathy
Emergent abilities
What kind of knowledge does an LLM have to have to be able to write a continuation of the following text?1
Assistant models

Trained (fine-tuned) in two stages to have conversations: turn-taking, question answering, not being [rude/sexist/racist], etc.
Foundation model has learned to predict all kinds of text, including both desirable and undesirable text.
Fine-tuning is a process narrow down the space of all possible output to only desirable, human-like dialogue.
Model is aligned with the values of the fine-tuner.
Instruction fine-tuning

Reinforcement learning from human feedback (RLHF)

How do Chatbots work?

- Designed to present the illusion of a conversation between two entities.
How do chatbots actually work?


An LLM is a role-play simulator

Stochastic generation
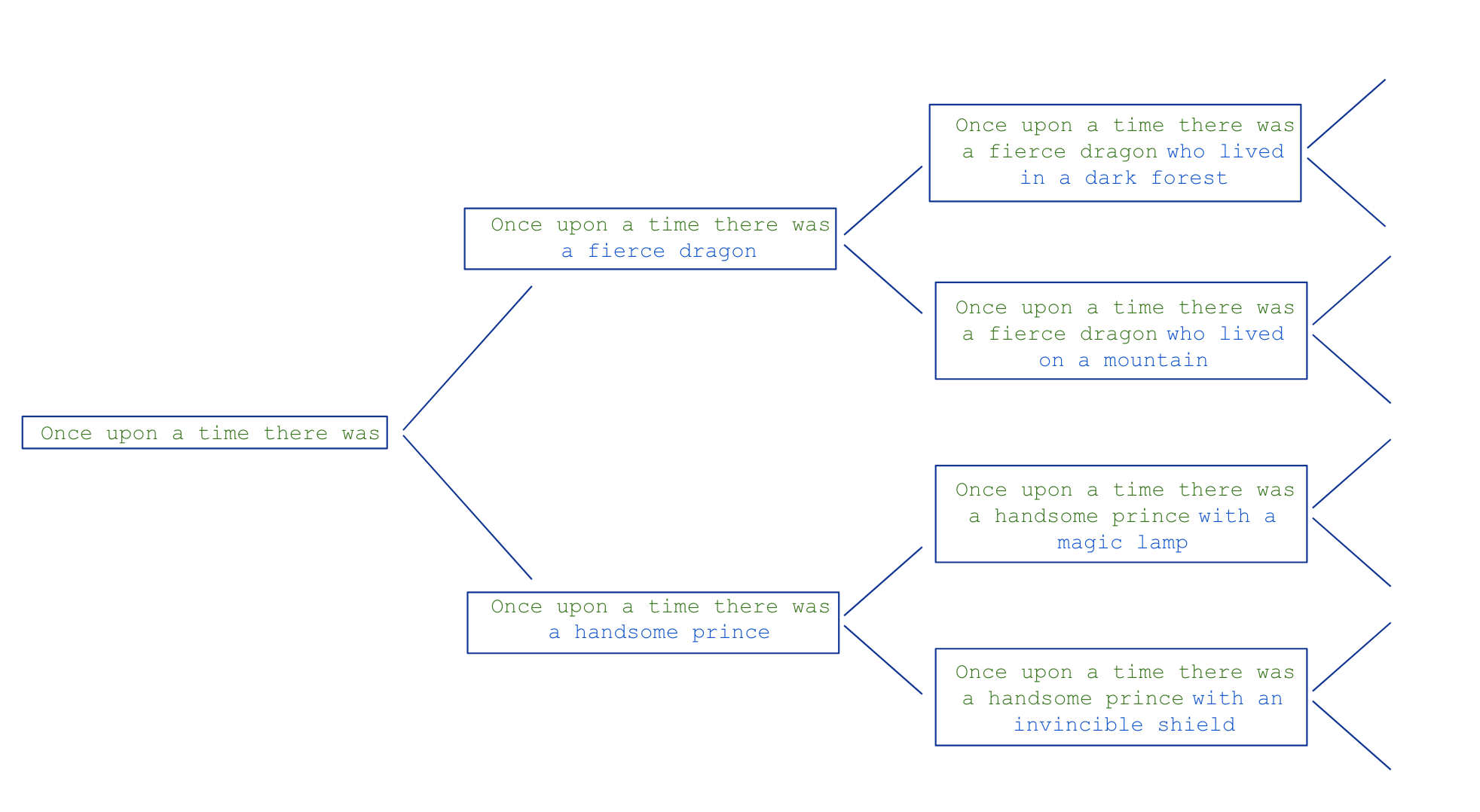
Hallucination

- LLMs can generate text that is not true, or not based on any real-world knowledge.
- This is known as “hallucination”. A better term would be “confabulation”.
Knowledge base
- A knowledge base is a collection of facts about the world.
- I can
ask(retrieve) andtell(store) facts.
Are LLMs knowledge bases?

- I can ask but the response is not verifiable.
- I can’t tell, i.e. can’t store new information (expensive/difficult to update with new knowledge).
- LLM can’t tell me where it got its information from.
- LLMs are models of knowledge bases, but not knowledge bases themselves.
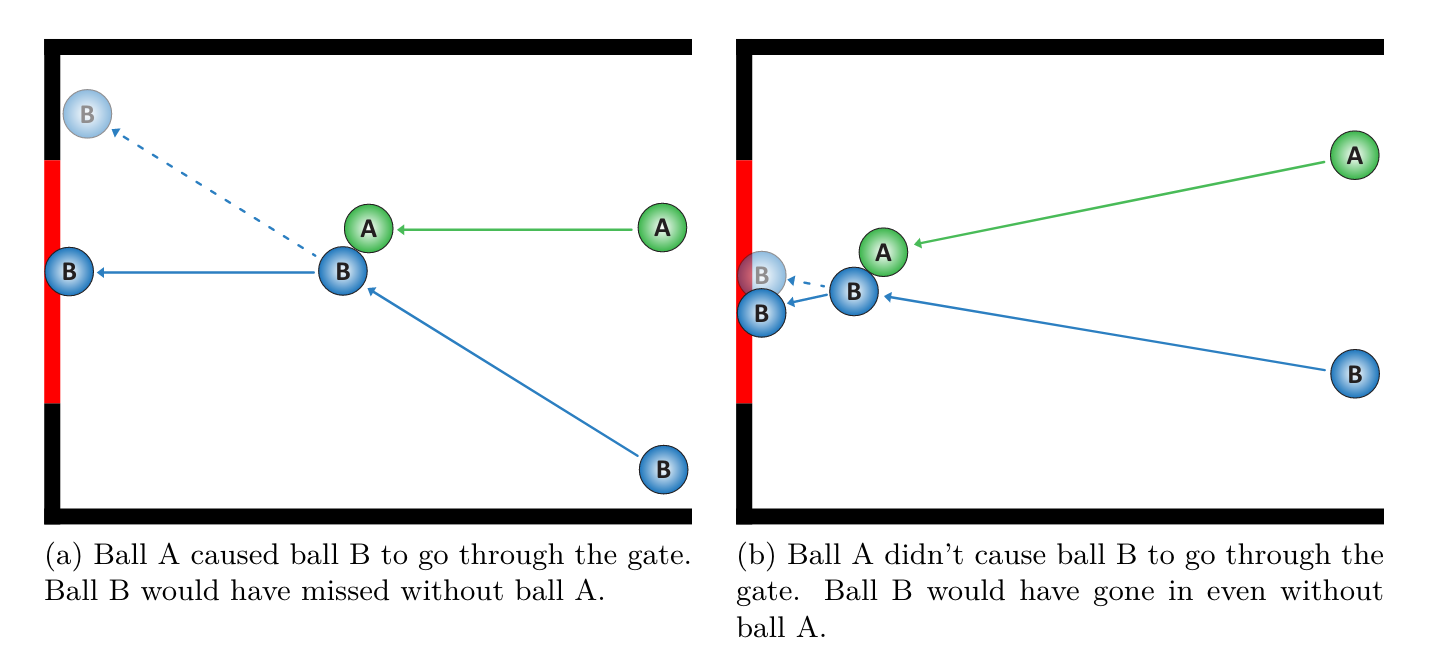
How do humans think?
E.g. physical reasoning

Prompting

Unlocking knowledge

- LLMs learn to do things they were not explicitly trained to do.
- Often, these capabilities need to be “unlocked” by the right prompt.
- What is the right prompt?
- The answer is very similar to what you would tell a human dialogue partner/assistant.
- You can increase the probability of getting the desired output by asking good questions or giving enough information.
Advanced LLM techniques
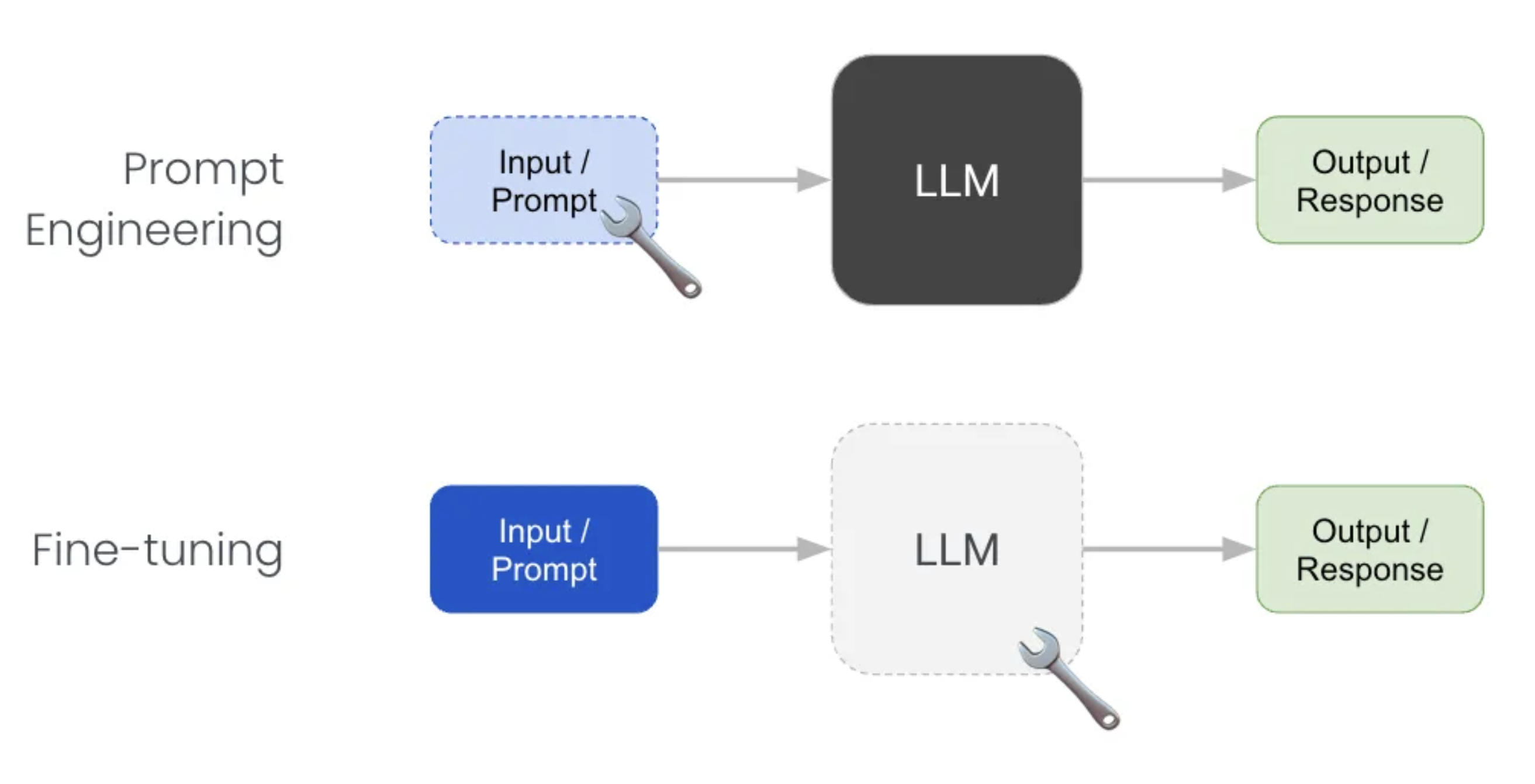
Retrieval-augmented generation (RAG)
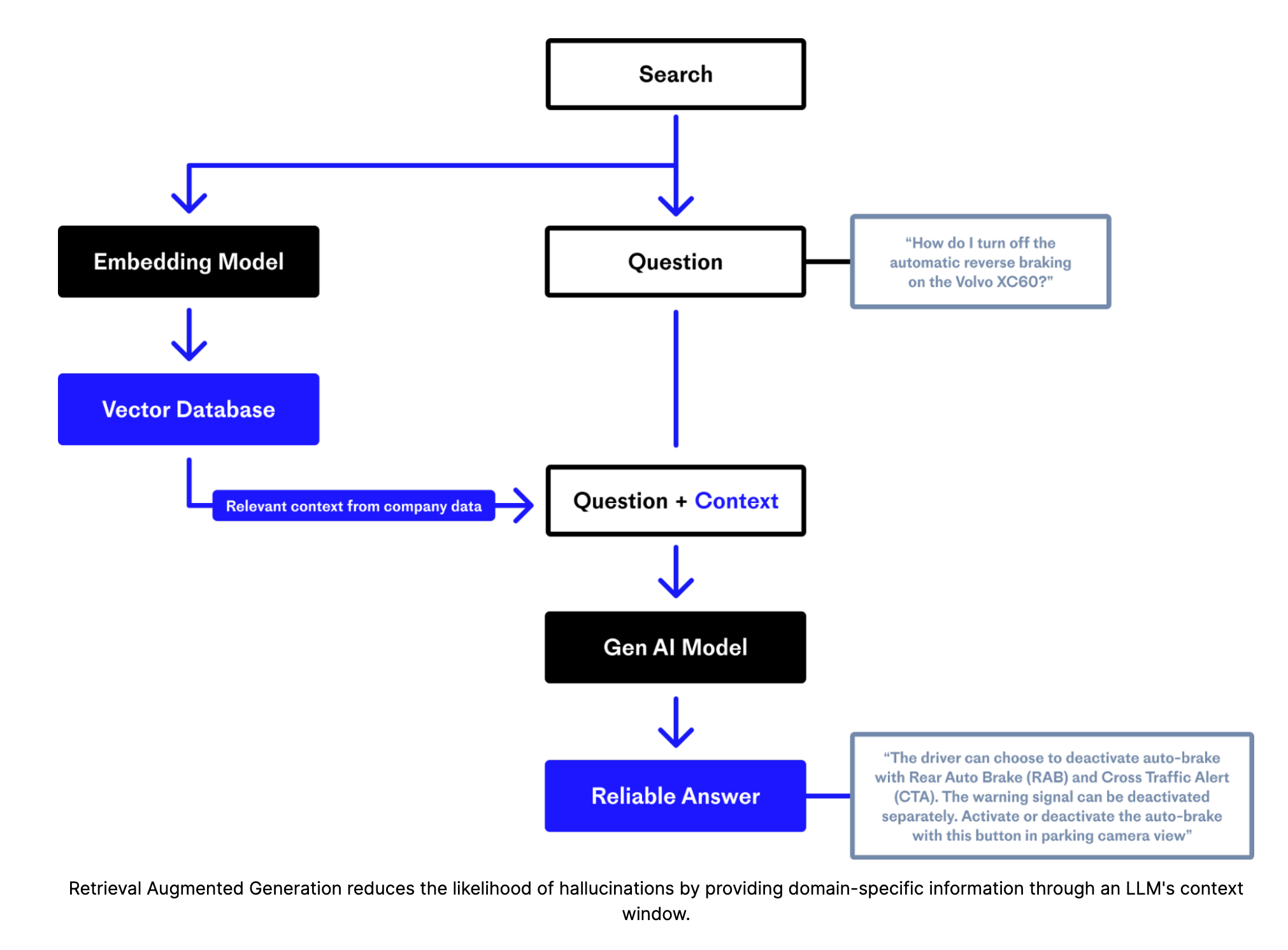
Figure courtesy of Pinecone
Multi-agent conversations

- DEMO: haiku writing team